Struggling with a slow database or skyrocketing hosting costs? If your database is hitting performance limits, database sharding might be the solution you need. Sharding splits your data into smaller chunks (shards) and distributes them across multiple servers, improving performance and scalability.
Key Takeaways:
- When to Shard: If your database exceeds 1TB, write throughput maxes out, or queries stay slow despite optimizations, sharding could help.
- Sharding Strategies: Choose between range-based (ideal for sequential data), hash-based (great for even distribution), or geographic (best for global operations).
- Shard Key Importance: A good shard key ensures balanced data distribution and efficient queries. Avoid low-cardinality or increasing-value keys.
- Implementation Tips: Plan thoroughly, test in staging, and minimize downtime during migration. Use tools like middleware to simplify routing and monitoring.
Sharding isn’t a simple fix - it adds complexity to your system. But for SMEs with growing data needs, it can boost performance by up to 5x and scale operations effectively. Read on to learn how to implement sharding step-by-step, optimize cross-shard queries, and maintain a healthy sharded database.
Sharding strategies: lookup-based, range-based, and hash-based
When to Consider Sharding for Your SME
Sharding can be a game-changer when traditional scaling methods no longer meet your database's demands. However, it's not a one-size-fits-all solution. Implementing sharding adds complexity to your infrastructure, and jumping into it too early can strain your team unnecessarily. The key is knowing when your database has outgrown simpler options like vertical scaling (upgrading server hardware) or using read replicas.
Warning Signs Your Database Needs Sharding
There are clear signs that indicate it's time to think about sharding. For instance, if your queries remain sluggish even with proper indexing, it’s a sign your server might be overwhelmed. Another red flag is when write throughput hits its limit - if incoming transactions surpass what your primary database node can handle, even after hardware upgrades, you've likely reached a bottleneck that read replicas alone can't resolve.
Storage issues are another trigger. If your database grows beyond 1TB or backup cycles take too long to complete, distributing data across multiple nodes becomes a necessity. Similarly, if you've maxed out your cloud provider’s instance sizes for CPU or RAM - hitting the "hard ceiling" of vertical scaling - horizontal scaling through sharding might be your only option.
Resource contention is another critical factor. Frequent timeouts, lock contention from concurrent transactions, or excessive disk I/O can occur when the active working set of data exceeds available RAM. A real-world example? In April 2024, PayPal's engineering team shared how their JunoDB system uses 1,024 shards to handle billions of daily transactions in global payment operations - a scale where a single node simply won't cut it.
| Indicator | Description | SME Impact |
|---|---|---|
| Query Latency | Slower query responses during standard operations | Poor user experience, risking customer churn |
| Write Saturation | Transaction rates exceeding 10,000 per second | System instability and potential data loss |
| Storage Ceiling | Database surpassing 1TB or slow backup processes | Operational fragility and recovery challenges |
| Hardware Limits | Maxed-out cloud instance sizes (CPU/RAM) | No further scaling without re-architecting |
Recognizing these warning signs allows you to evaluate whether the benefits of sharding outweigh its added complexity and costs.
Cost vs. Complexity Trade-offs
Before committing to sharding, it’s essential to weigh the costs and complexities involved. Start by exploring simpler alternatives. Vertical scaling is straightforward but can be up to 70% more expensive than adding horizontal nodes. Read replicas work well for read-heavy workloads but won't help with write bottlenecks. Offloading files to cloud storage like Amazon S3 or moving analytics to a data warehouse can also provide temporary relief.
Sharding shifts the workload from hardware to application logic, meaning developers must manage data routing, cross-shard queries, and referential integrity manually. Operational demands increase as teams juggle multiple database instances, backups, and rebalancing tasks instead of maintaining a single system. For example, one fintech startup spent $47,000 on a custom sharding solution, which ultimately saved them significant licensing fees.
That said, the rewards can be substantial. Sharding often improves query response times by 3–5x through parallel processing, and it supports predictable, linear cost growth by allowing you to add commodity hardware as needed. In 2021, pharmaceutical giant McKesson transitioned from a monolithic setup to MongoDB Atlas, scaling operations 300x to track 1.2 billion containers annually - all without latency issues. For SMEs with naturally segmented data - such as by customer, region, or business unit - sharding becomes much more manageable.
"Salesforce, on the other hand, is a multi-tenant system. That means we actually have a really simple way to do it: we shard by customer organization." - Ian Varley, Principal Architect at Salesforce
3 Main Sharding Strategies
When deciding on the right sharding strategy, it’s important to consider your query patterns, how your data is distributed, and your system’s growth trajectory. Below, we break down three key strategies to help you make an informed choice.
Range-Based Sharding
This approach organizes data into sequential chunks based on the shard key. For example, you could divide data by date ranges or sequential customer IDs. It's a great option for queries targeting specific ranges, like fetching all orders from a particular month. However, a potential downside is the risk of creating "hotspots." If most new data falls into a narrow range, one shard might end up handling a disproportionate amount of work. To avoid this, keep an eye on shard performance and rebalance when necessary.
Hash-Based Sharding
Hash-based sharding uses a mathematical hash function to evenly distribute data across shards, regardless of its natural order. This method ensures balanced workloads, especially for write-heavy operations, by preventing clustering. However, it’s not ideal for range queries. Since related records are scattered across multiple shards, retrieving a range often requires a scatter-gather process, which can slow things down. Additionally, adding or removing shards requires rehashing and migrating data, which can be resource-intensive.
"Sharding with MongoDB allows you to seamlessly scale the database as your applications grow beyond the hardware limits of a single server, and it does so without adding complexity to the application." - Mat Keep and Henrik Ingo of MongoDB
Geographic Sharding
Geographic sharding divides data based on physical location. This method reduces latency by keeping data closer to users and helps businesses comply with regional data regulations. It’s especially useful for global operations. That said, uneven growth across regions can lead to imbalanced shard sizes, and cross-region queries - like creating a global sales report - become more complex when data is spread across continents. Despite these challenges, this strategy is particularly appealing for global businesses looking to improve user experience and meet compliance needs.
"A sharded approach is more resilient. If one of the servers is offline, the remaining shards are still accessible." - Jeff Novotny from Linode
| Strategy | Best For | Performance Strength | Main Drawback |
|---|---|---|---|
| Range-Based | Sequential data (dates, IDs) | Fast range-based queries | Risk of creating "hotspots" |
| Hash-Based | Even data distribution | Balanced workloads | Inefficient for range queries |
| Geographic | Global user bases | Low latency for local queries | Complex rebalancing with uneven growth |
How to Choose and Use Shard Keys
After deciding on your sharding strategy, the next big step is picking the right shard key. This key is what determines how your data gets distributed across shards, directly affecting how efficiently your database performs. The shard key plays a huge role in query speed, scalability, and overall balance. If it's chosen poorly, you could end up with uneven data distribution or inefficient queries, like scatter-gather operations that hit every shard instead of just one. And trust me, scatter-gather queries are not the way to go if you're aiming for efficiency.
What Makes a Good Shard Key
To get the most out of your shard key, there are a few things to keep in mind:
- High cardinality is a must. The shard key should have plenty of unique values to allow for horizontal scaling. For example, using a field like "continent" (with only seven unique values) would limit your cluster to just seven effective shards. Not ideal.
- Even distribution matters. Even if your key has many unique values, it's a problem if certain values show up way more often than others. This can lead to "jumbo chunks" that slow things down. A good shard key should align with your most common queries so that the database can route them to specific shards instead of broadcasting them everywhere.
- Stability is key. The values in your shard key shouldn't change often. Why? Because changing a shard key value usually means moving the entire document or row to a different shard, which is resource-heavy.
- Avoid increasing values. Fields like timestamps or auto-incrementing IDs might seem like good options, but they can create bottlenecks by funneling all new data into a single shard. If you need to use such fields, hashed sharding can help spread the data more evenly.
If no single field meets all these criteria, you can combine multiple fields into a compound shard key to create more unique combinations and achieve better distribution.
| Factor | Recommended Characteristic | Impact of Failure |
|---|---|---|
| Cardinality | High (many unique values) | Limits scaling; adding shards won't improve performance |
| Frequency | Low (even value distribution) | Leads to bottlenecks and uneven data distribution |
| Monotonicity | Non-monotonic (or use hashing) | Causes write hotspots on specific shards |
| Query Pattern | Present in common queries | Forces scatter-gather queries, which consume resources across the entire cluster |
| Stability | High (values rarely change) | Requires costly distributed transactions to relocate data |
By focusing on these factors, you’ll avoid many of the common issues that can arise with poorly chosen shard keys.
Shard Key Mistakes to Avoid
One frequent mistake is selecting a low-cardinality field. For instance, using a "continent" field to shard your data limits the cluster to just seven effective shards. Adding more shards won’t improve scaling in this case. Similarly, choosing a field with a small number of highly frequent values can lead to jumbo chunks that are hard to split, creating data imbalances.
Another common error is using increasing values without hashing. This funnels all new inserts to a single shard, creating a write bottleneck. On top of that, queries that don’t include the shard key force the system to broadcast requests to every shard. This scatter-gather method becomes less efficient as your cluster grows.
Thankfully, modern tools can help. For example, MongoDB 7.0+ includes an analyzeShardKey command that evaluates metrics like cardinality, frequency, and monotonicity based on sampled queries. This feature helps you make smarter, data-driven decisions before finalizing your shard key. In Oracle systems, if you need to update a shard key, enabling ROW MOVEMENT allows the database to automatically migrate records to the correct shard. Lastly, when loading data into a new sharded collection, pre-splitting chunks and distributing them across all shards can save you from the headache of massive migrations later on.
Step-by-Step Sharding Implementation
Once you've decided on your shard key and sharding strategy, it's time to bring your plan to life. This phase builds on earlier decisions and involves executing your strategy in a way that minimizes disruption to your systems. Careful planning and execution are essential to ensure a smooth transition. Here's how to tackle it effectively.
Planning Your Sharding Project
Before diving into the process, confirm that sharding is genuinely necessary. Sharding should only be considered when your application data exceeds the storage capacity of a single node or when high read/write volumes lead to slow response times or timeouts. Many small to mid-sized enterprises (SMEs) often rush into sharding without exploring simpler alternatives.
First, evaluate whether other scaling solutions, such as vertical scaling, caching, or using read replicas, might solve your issues.
If sharding is the right choice, focus on a few critical elements during the planning phase. Start by analyzing the cardinality and access frequency of your chosen shard key. A poorly chosen shard key can lead to database hotspots, where one shard is overwhelmed while others remain underutilized. Next, decide how many physical shards you'll need. This decision should factor in your expected data growth, hardware capabilities, and requirements for high availability. Lastly, plan for a robust routing layer or middleware to ensure queries are directed to the correct shards and to handle cross-shard joins efficiently.
Keep in mind that sharding is a one-way street. Once a database is sharded, reverting to a non-sharded model is extremely challenging and often requires merging data from backups, which can be costly and time-consuming. Make sure this is the right move before proceeding.
With a solid plan in place, you can move on to the careful task of migrating your data.
Migrating to Sharded Databases
Migration generally involves two main steps: schema migration and data migration. During this phase, you’ll need to update your application code to incorporate the shard key and make adjustments to connection pooling as necessary.
To ensure a smooth migration, start by disabling the balancer if you're working with systems like MongoDB. This prevents chunk migration and metadata changes during the transition. For configuration replica sets, migrate secondary config servers first, then demote the primary. When it comes to the shards themselves, migrate them sequentially. Begin with non-primary replica set members, and then demote the primary to trigger a quick election, which minimizes downtime for write operations.
Batch processing can help manage resource usage during migration, and having rollback mechanisms in place will safeguard against unexpected issues. Once the migration is complete, immediately implement monitoring tools to track shard health and query performance. Set up alerts to catch potential bottlenecks early.
Minimizing Downtime During Migration
Downtime can disrupt operations and impact customer satisfaction, so choosing the right migration approach is critical. After migrating your database, keeping downtime to a minimum is essential to maintain business continuity.
Offline migration involves marking partitions as read-only or offline, transferring the data, and then bringing the new shards online. This approach reduces the risk of data contention or inconsistency but does require some downtime. On the other hand, online migration transfers data item-by-item while the system remains live. Although this method minimizes disruption, it adds complexity since your application must handle data stored in two locations simultaneously.
Many SMEs opt for a hybrid approach. This involves migrating data while keeping the original database active, often by using a temporary read-only mode or dual-write setup. No matter which method you choose, thoroughly test your process in a staging environment before working with production data. Schedule the final cutover during periods of low traffic to minimize the impact on your operations.
sbb-itb-bec6a7e
Handling Cross-Shard Queries
When your data is spread across multiple shards, queries without a shard key can trigger a broadcast query, significantly increasing latency - sometimes by 300–500%. Every sharded request has to go through a router or middleware, which adds a baseline latency "tax" to each operation. Let’s explore how to tackle these challenges and improve the efficiency of cross-shard queries.
Optimizing Queries Across Multiple Shards
To get the best performance from cross-shard queries, always include the shard key in your WHERE clause. This allows the router to pinpoint the specific shard needed, avoiding the need to broadcast the query across all shards. It’s a small adjustment that makes a big difference in maintaining performance at scale.
For situations where cross-shard joins can’t be avoided, denormalization becomes a key strategy. By replicating frequently accessed "global" data - like product categories, country codes, or measurement conversion rates - to every shard, you eliminate the need for cross-shard joins. Each shard can handle these joins locally, improving speed and reducing complexity. While this approach does introduce some data redundancy, the performance benefits often outweigh the additional storage costs.
Caching is another effective way to cut down on cross-shard operations. Adding a caching layer - using tools like Redis for "hot" data - can significantly reduce the need for repetitive cross-shard retrievals. For example, caching commonly joined data, such as product categories, can prevent repeated expensive operations.
There are exceptions to the "avoid broadcast query" rule. Large analytical queries or reports that require data from all shards can actually benefit from broadcast queries, especially when they leverage parallel processing. Just ensure these operations are scheduled during off-peak times to minimize their impact on regular database usage.
When query-level optimizations aren’t enough, middleware can play a crucial role in managing cross-shard communication effectively.
Using Middleware to Simplify Query Management
Middleware acts as a bridge between your application and the sharded database, letting you connect through a single endpoint instead of managing separate connections for each shard. Tools like Vitess or MongoDB’s mongos handle the heavy lifting - parsing commands, identifying shard keys, and routing queries to the appropriate shard.
For small and medium-sized enterprises (SMEs), middleware can greatly simplify operations. Instead of embedding custom routing logic into your application, middleware takes care of tasks like aggregating cross-shard data, handling errors when shards are unavailable, and maintaining routing metadata. Middleware solutions such as Vitess also make it easier for legacy systems to scale without requiring extensive code rewrites.
However, there’s a trade-off: middleware introduces a small latency of about 8 milliseconds per query. This delay is usually a reasonable compromise compared to the time and resources needed to build custom routing logic. On average, setting up middleware takes one to two weeks and costs around $800 or more per month.
Even with middleware, following best practices is critical. Always include shard keys in your queries to avoid unnecessary broadcast operations. Configure connection pools to operate at 50–70% capacity to prevent "connection storms" that could lead to outages. Additionally, integrating middleware with monitoring tools like Prometheus or Grafana helps you track shard health and identify performance bottlenecks before they escalate into bigger issues.
Monitoring and Maintaining Sharded Databases
Once your sharded database is up and running, keeping it in top shape requires consistent monitoring and smart maintenance practices. Here's a closer look at the essential metrics to track and the steps to automate and scale your database operations.
Tracking Shard Performance Metrics
To ensure your shards perform smoothly, it's crucial to keep an eye on a few key metrics. Start with hardware health - monitor CPU usage and RAM allocation, particularly the working set (the data actively accessed). If the working set outgrows the available RAM, you'll face increased disk I/O, which can drag down performance.
Next, check data distribution across shards. Uneven data distribution, where one shard bears a heavier load than others, can lead to performance bottlenecks. Metrics like logical data size and document count for each shard help identify these imbalances.
Query patterns also deserve attention. Scatter-gather queries, which broadcast to all shards, are especially problematic. As Mat Keep and Henrik Ingo from MongoDB explain:
"In sharded systems, queries that cannot be routed based on shard key must be broadcast to all shards for evaluation... they do not scale linearly as more shards are added".
Keeping tabs on these metrics complements earlier efforts to optimize cross-shard queries.
| Metric Category | Key Metrics to Track | Purpose for SMEs |
|---|---|---|
| Hardware Health | CPU Usage, RAM (Working Set), Disk I/O | Spot when a shard needs more resources or vertical scaling |
| Data Balance | Shard Data Size, Chunk Count, Document Count | Identify overloaded shards and maintain balance |
| Query Efficiency | Scatter-Gather Ratio, Targeted Query Rate | Improve shard key design to minimize query overhead |
| Operations | Read/Write Throughput, Queued Operations | Ensure the database can handle application demand |
| Cluster Metadata | Config Server Latency, Balancer Errors | Verify the cluster's control system is functioning properly |
Automating Database Maintenance
To reduce manual effort, automate repetitive maintenance tasks. MongoDB's background balancer process, for instance, redistributes data chunks across shards to maintain balance automatically. When setting up new sharded collections, it's a good idea to pre-split and distribute empty chunks across all shards to avoid initial performance hiccups.
Managed database services can take the heavy lifting off your plate by automating provisioning, scaling, and rebalancing. A standout example is McKesson, which transitioned to MongoDB Atlas in 2025. This shift enabled them to scale operations 300x, manage tracking data for 1.2 billion drug containers annually, and ensure compliance - all without latency issues.
Real-time observability tools like Prometheus, Grafana, and Datadog are invaluable for monitoring metrics like query speeds, disk I/O, and memory usage. These tools can trigger automated responses when thresholds are breached, ensuring your database stays ahead of potential issues.
Once monitoring and maintenance are automated, you’ll be better prepared to plan for growth and manage shard rebalancing.
Adding and Rebalancing Shards
As your workload grows, adding new shards or redistributing data becomes necessary to maintain performance. But this process requires careful planning to avoid disruptions.
Before adding shards, ensure your cluster has enough headroom - CPU load should be below 80% and I/O capacity under 50%. Resharding operations also demand significant temporary storage. Plan for at least [(collection size + index size) * 2] / number of shards in available storage on each shard to handle data duplication during migration.
For new collections, pre-splitting and distributing empty chunks across shards helps prevent all new data from piling onto a single shard. For existing collections, use performance metrics or heat maps to identify overloaded chunks, then redistribute them to less active shards.
Keep in mind that during the final commit phase of resharding, applications may experience a brief write interruption - usually about two seconds. To minimize impact, schedule these tasks during low-traffic periods and avoid heavy multi-shard query workloads at the same time.
Modern cloud databases offer the flexibility to scale shards independently, allowing you to allocate more IOPS or larger cluster tiers to specific shards based on workload demands.
| Requirement | Recommended Threshold/Value |
|---|---|
| CPU Load | Below 80% |
| I/O Capacity | Below 50% |
| Minimum Oplog Window | 24 Hours |
| Write Block Duration | ~2 Seconds |
| Collection Size Threshold | 3 TB |
Sharding Strategies Comparison and Best Practices
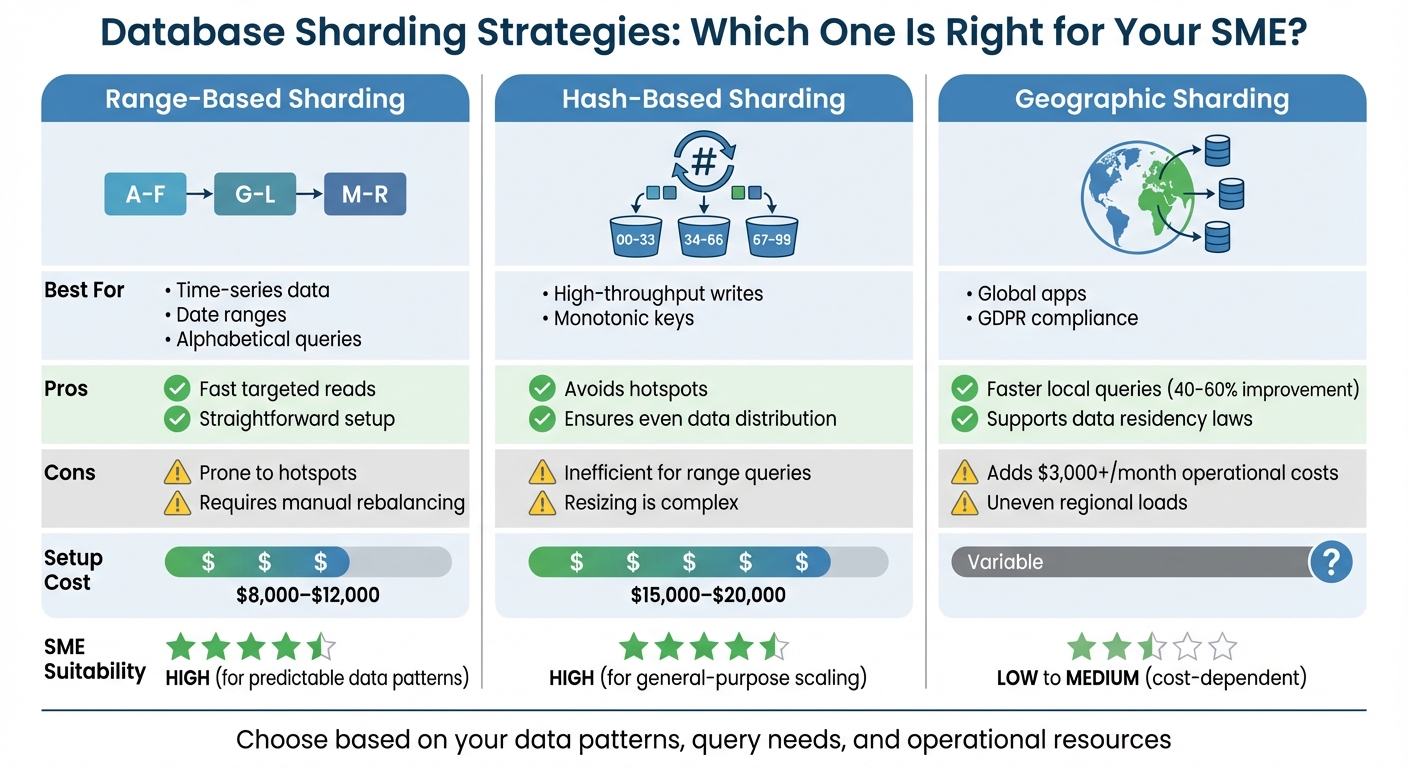
Database Sharding Strategies Comparison: Range-Based vs Hash-Based vs Geographic
Choosing the right sharding strategy comes down to understanding your data patterns, query needs, and operational resources. Below, we break down the strengths, challenges, and costs of each approach.
Range-based sharding works well for queries involving specific ranges, such as filtering orders by date or searching customer names alphabetically. This method keeps related data together on the same shard, which speeds up queries. However, it’s prone to imbalances - if most traffic targets a single range (like recent orders), that shard can get overwhelmed while others sit idle.
Hash-based sharding solves the hotspot problem by running the shard key through a hash function (e.g., MD5), distributing data evenly across all shards. This ensures uniform write distribution, even for auto-incrementing IDs or timestamps. The trade-off? Related data ends up spread across multiple shards, making range queries slower and potentially increasing query latency by 300% to 500%.
Geographic sharding is perfect for global operations that require compliance with data residency laws. For instance, European customer data can be stored in EU-based shards, while U.S. data stays domestic. This setup can reduce latency for local queries by 40–60%. However, it adds significant costs - over $3,000 per month for multi-region cloud setups - and requires complex routing logic. For smaller businesses without a global presence, this strategy might introduce unnecessary complications.
Sharding Strategy Comparison Table
| Strategy | Best For | Pros | Cons | Setup Cost | SME Suitability |
|---|---|---|---|---|---|
| Range-Based | Time-series data, date ranges, alphabetical queries | Fast targeted reads; straightforward setup | Prone to hotspots; requires manual rebalancing | $8,000–$12,000 | High for predictable data patterns |
| Hash-Based | High-throughput writes, monotonic keys | Avoids hotspots; ensures even data distribution | Inefficient for range queries; resizing is complex | $15,000–$20,000 | High for general-purpose scaling |
| Geographic | Global apps, GDPR compliance | Faster local queries (40–60%); supports residency laws | Adds $3,000+/month; uneven regional loads | Variable | Low to Medium (cost-dependent) |
Before diving into sharding, it’s essential to weigh these trade-offs carefully. Simpler solutions like vertical scaling or read replicas might address your needs without the irreversible complexity of sharding. Use this comparison as a guide to determine the best approach for your business.
Conclusion
Deciding to shard your database is no small matter. It's a step to consider when your data surpasses 1TB, transactions exceed 10,000 per second, or query latency stubbornly stays above 500ms, even after optimization efforts. Timing is everything - shard too soon, and you’ll introduce unnecessary complexity; wait too long, and you might face a rushed, high-risk migration under pressure.
Before diving into sharding, explore simpler options like vertical scaling, adding read replicas, or implementing caching. If sharding becomes unavoidable, selecting the right shard key is a critical decision that can make or break the process.
When it’s time to shard, the implementation path should align with your organization’s needs and resources. Small to medium enterprises (SMEs) have several options: automated distributed SQL databases, which can be set up in as little as 2–4 hours; middleware solutions for adapting legacy systems, typically requiring 1–2 weeks; or custom application-level sharding, a more time-intensive approach taking 3–6 months. Each choice comes with its own balance of cost, complexity, and control.
Sharding inevitably shifts complexity to your application and DevOps teams. This means you'll need robust monitoring systems, careful rebalancing strategies, and thorough planning for handling cross-shard queries. To mitigate risks, prepare your infrastructure for the increased operational load by testing at least three times your expected traffic levels. During migration, dual writes are essential, and a solid rollback plan should always be in place.
While sharding can boost query response times by 3–5× and enable systems to handle over 1 million queries per second, it’s crucial to weigh these benefits against the added complexity it brings.
FAQs
How can I tell if my SME needs to implement database sharding?
If your small or medium-sized enterprise (SME) is grappling with issues like slower query response times, write throughput nearing its limits, or a single server running out of storage and CPU capacity, it might be time to consider database sharding. Other red flags include rising costs from vertical scaling or data and traffic volumes that are simply too much for one database to handle.
Sharding divides your database into smaller, more manageable pieces spread across multiple servers. This setup can boost performance and make scaling easier, especially for SMEs dealing with large datasets or sudden spikes in traffic.
What’s the best way to choose a sharding strategy for my business?
To choose the best sharding strategy for your needs, start by diving into your business's data and workload patterns. Take a close look at the size of your data, the balance between read and write operations, and any specific compliance or latency requirements you must meet. If your database is hitting limits like high CPU usage, storage constraints, or I/O bottlenecks, sharding could be a smart way to scale horizontally without the expense of upgrading your server.
A critical piece of this puzzle is the shard key - it’s what determines how your data gets distributed and how efficiently your queries perform. The ideal shard key has a few key traits: high cardinality (lots of unique values), balanced frequency (no single value dominates), and non-monotonic growth (avoiding keys like timestamps that grow continuously and cause hotspots). Here are some common sharding strategies to consider:
- Hash-based sharding: Distributes data evenly across shards, making it a good option for workloads that don’t rely on strong data locality. However, it can lead to more cross-shard queries.
- Range-based sharding: Works well for queries targeting specific ranges, like date intervals. Be cautious, though - if your range key grows in a predictable way, like a timestamp, it can create hotspots.
- Composite sharding: Uses a combination of fields (e.g., region + customer type) to achieve a better balance in data distribution while keeping queries efficient.
Before rolling out your sharding approach fully, test it on a smaller scale. Keep an eye on how well data is balanced, how queries perform, and how complex operations become. Adjust as you go to ensure your solution scales smoothly and remains cost-efficient as your business evolves.
What are the key benefits and challenges of database sharding for small and medium businesses?
Database sharding is the process of breaking a large database into smaller, independent pieces, known as shards, which are then distributed across multiple servers. For small and medium businesses (SMBs), this method can be a smart way to manage increasing data demands and user traffic without the need for expensive infrastructure upgrades.
Why Sharding Works for SMBs
Sharding offers horizontal scalability, meaning businesses can add more affordable servers instead of investing in costly high-performance hardware. By spreading data and processing across multiple shards, it also boosts performance - queries run faster, and transaction throughput improves. Another key advantage is fault isolation: if one shard encounters an issue, it won’t disrupt the entire system.
The Challenges to Consider
On the flip side, sharding isn’t a simple plug-and-play solution. It requires careful planning to define shard keys and ensure data is distributed efficiently. Handling cross-shard queries can be tricky, often slowing performance and requiring additional development work. Backup and migration processes also become more intricate, and implementing sharding too early or too late can lead to inefficiencies.
For SMBs anticipating rapid data growth, sharding can be a practical and cost-efficient strategy. However, its success hinges on detailed preparation and consistent management.


